El euskera es el idioma que tiene un mayor número de significados en Wikidata
Se encuentra en el sexto lugar en cuanto al número de lexemas
Ocupa el segundo puesto en cuanto al número de formas de las palabras
Es el principal idioma en cuanto al número de significados
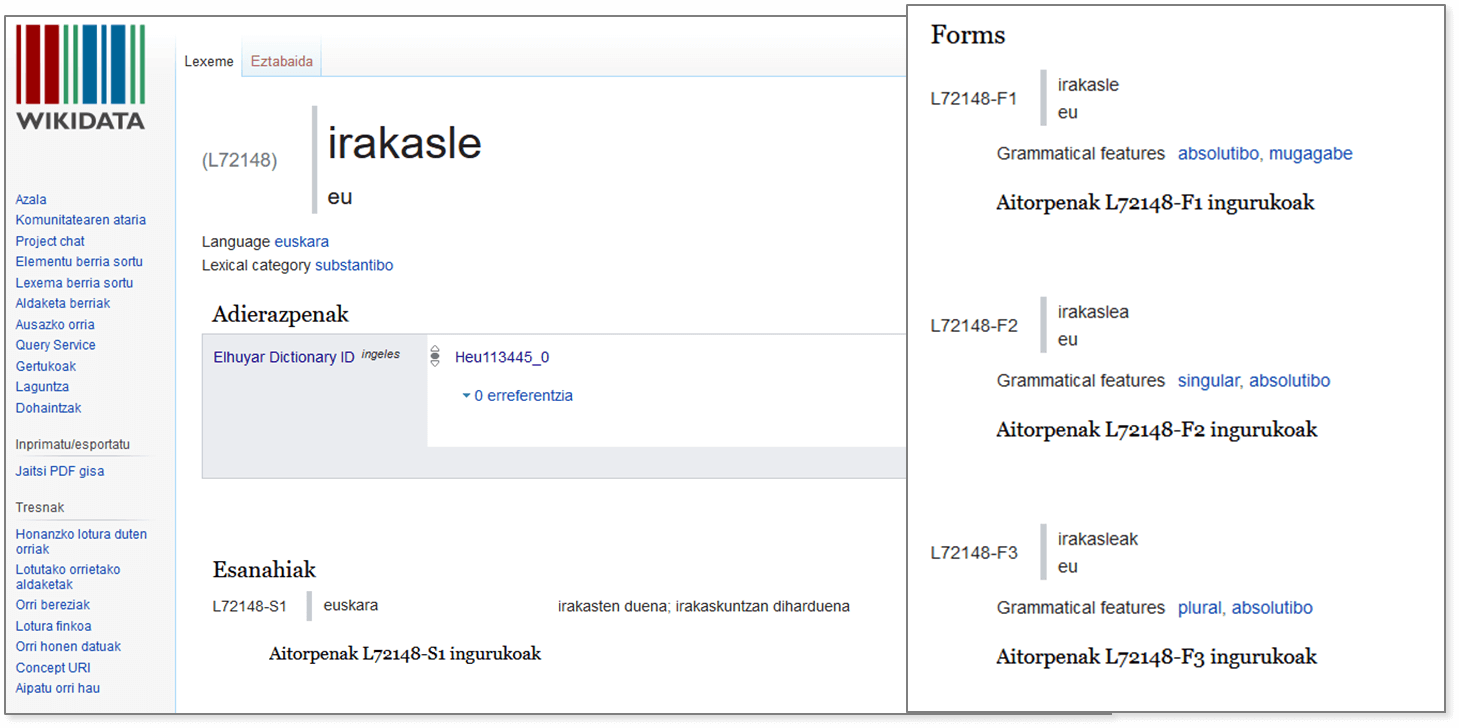
Gracias a la colaboración entre Euskal Wikilarien Kultur elkartea y Elhuyar, de entre todas las lenguas incluidas en Wikidata el euskera se encuentra en el sexto lugar en cuanto al número de lexemas, ocupa el segundo puesto en cuanto al número de formas de las palabras (teniendo en cuenta todas las formas que se crean al declinar cada lexema) y es el principal idioma en cuanto al número de significados, por delante del inglés, el castellano y el francés, entre otros.
Wikidata es una enorme base de datos que se edita de forma colaborativa. Lo gestiona la Fundación Wikimedia, con el fin de utilizarlo en sus proyectos; por ejemplo, en Wikipedia.
Se puso en marcha en 2012, y hemos ido alimentándolo progresivamente. Hace dos años, por ejemplo, incluimos alrededor de 6.500 conceptos provenientes del Diccionario Enciclopédico de la Ciencia y la Tecnología, así como varios vídeos de nuestro programa de televisión, Teknopolis.
A lo largo de estos últimos años, Wikidata ha comenzado a guardar nuevos tipos de datos, correspondientes a varios idiomas, en una estructura similar al de los diccionarios. Toda esta información se guarda clasificada en tres grupos: raíces de palabras (entradas de diccionario o lexemas), formas (las formas que puede tomar cada palabra en función del caso de declinación) y significados o definiciones.
Gracias a la colaboración entre Euskal Wikilariak Kultur Elkartea y Elhuyar, hemos podido incluir en Wikidata un gran número de palabras o lexemas (de la categoría de los sustantivos) de nuestro Ikaslearen Hiztegia, diccionario dirigido especialmente al alumnado. En total, se han añadido 10.000 lexemas, 65 formas de cada uno de estos lexemas (de todos los casos de declinación, en singular, plural e indeterminado) y sus definiciones.
Gracias a este trabajo, ahora resulta más fácil identificar las palabras en euskera, por ejemplo, en los textos de Wikipedia, y en un corto plazo se podrán desarrollar nuevas tecnologías a partir de estas bases de datos.
El código de programación desarrollado por el grupo de trabajo I+D de Elhuyar para este proyecto está disponible en GitHub.









